目录
LongformerForTokenClassification调通
将7分类的预训练模型改为2分类
利用分类标签取出token对应子词
将token转换为完整单词取出
LongformerForTokenClassification调通
对应文档:
https://huggingface.co/docs/transformers/en/model_doc/longformer#transformers.LongformerForTokenClassification
下载预训练模型:
https://huggingface.co/docs/transformers/en/model_doc/longformer#transformers.LongformerForTokenClassification
修改使用模型预测与训练时的输出获取
| from transformers import AutoTokenizer, LongformerForTokenClassification import torch # tokenizer = AutoTokenizer.from_pretrained("brad1141/Longformer-finetuned-norm") # model = LongformerForTokenClassification.from_pretrained("brad1141/Longformer-finetuned-norm") tokenizer = AutoTokenizer.from_pretrained("tmp/Longformer-finetuned-norm") model = LongformerForTokenClassification.from_pretrained("tmp/Longformer-finetuned-norm") inputs = tokenizer( "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt" ) #预测 with torch.no_grad(): outputs=model(**inputs) # 如果输出是元组,可以手动解析 if isinstance(outputs, tuple): logits, = outputs else: logits = outputs.logits predicted_token_class_ids = logits.argmax(-1) # Note that tokens are classified rather then input words which means that # there might be more predicted token classes than words. # Multiple token classes might account for the same word predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]] predicted_tokens_classes print("predicted_tokens_classes:", predicted_tokens_classes) # 训练 labels = predicted_token_class_ids # loss = model(**inputs, labels=labels).loss outputs = model(**inputs, labels=labels) if isinstance(outputs, tuple): loss,logits = outputs else: loss = outputs.loss round(loss.item(), 2) print("loss:", round(loss.item(), 2)) |
目前输出是NER任务的针对每一个token分类:
| predicted_tokens_classes ['Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence', 'Evidence'] |
Debug很重要的一步是看模型输出的各个维度什么意思, 这个可以从源文件和文档找,
此处longformer
logits (torch.FloatTensor of shape (batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax).
将7分类的预训练模型改为2分类
例子中的logits是[1, 12, 7], 其中sequence_length是句子中所有token的数量. config.num_labels 由config文件的id2label计算:
| "id2label": { "0": "Lead", "1": "Position", "2": "Evidence", "3": "Claim", "4": "Concluding Statement", "5": "Counterclaim", "6": "Rebuttal" }, |
此处将config原件保存副本, 然后修改类别为2个
| "id2label": { "0": "Non-dataset description", "1": "Dataset description" }, |
为了将 Longformer 的输出从 7 分类修改为 2 分类,需要调整模型的分类层(classifier layer):
加载预训练的 LongformerForTokenClassification 模型。
修改模型的分类层。
重新初始化模型的分类层。
| # 修改分类层为2分类 model.num_labels = 2 model.classifier = nn.Linear(model.config.hidden_size, model.num_labels) # 初始化分类层权重 model.classifier.weight.data.normal_(mean=0.0, std=model.config.initializer_range) if model.classifier.bias is not None: model.classifier.bias.data.zero_() |
报错:
| Some weights of LongformerForTokenClassification were not initialized from the model checkpoint at tmp/Longformer-finetuned-norm and are newly initialized: ['longformer.pooler.dense.weight', 'longformer.pooler.dense.bias'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference. Traceback (most recent call last): File "d:/Projects/longformer/tests/try_tkn_clsfy.py", line 7, in <module> model = LongformerForTokenClassification.from_pretrained("tmp/Longformer-finetuned-norm") File "D:\Users\laugo\anaconda3\envs\longformer\lib\site-packages\transformers\modeling_utils.py", line 972, in from_pretrained model.__class__.__name__, "\n\t".join(error_msgs) RuntimeError: Error(s) in loading state_dict for LongformerForTokenClassification: size mismatch for classifier.weight: copying a param with shape torch.Size([7, 768]) from checkpoint, the shape in current model is torch.Size([2, 768]). size mismatch for classifier.bias: copying a param with shape torch.Size([7]) from checkpoint, the shape in current model is torch.Size([2]). |
还没有运行到修改分类层就报错了,
在加载模型LongformerForTokenClassification.from_pretrained这一步报错. 因为其中需要读取config.num_labels, 此时config.num_labels是2, 与它不匹配
Config中的Id2label加载时候先不改后面再代码中再改
| model.config.id2label = {0: 'Non-dataset description', 1: 'Dataset description'} model.config.label2id = {'Non-dataset description': 0, 'Dataset description': 1} |
还有一个警告:
| Some weights of LongformerForTokenClassification were not initialized from the model checkpoint at tmp/Longformer-finetuned-norm and are newly initialized: ['longformer.pooler.dense.weight', 'longformer.pooler.dense.bias'] |
手动初始化权重
| model.longformer.pooler.dense.weight.data.normal_(mean=0.0, std=model.config.initializer_range) model.longformer.pooler.dense.bias.data.zero_() |
得到输出:
| predicted_tokens_classes ['Dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description'] |
利用分类标签取出token对应子词
现在将分类为1, 即predicted_tokens_classes 为'Dataset description'的取出.
| for k, j in enumerate(predicted_tokens_classes):# j is label, k is index if (len(predicted_tokens_classes)>1): if (j=='Dataset description') & (k==0): # print("j:",j,";k:",k) #if it's the first word in the first position #print('At begin first word') begin = tokenized_sub_sentence[k] kword = begin elif (j=='Dataset description') & (k>=1) & (predicted_tokens_classes[k-1]=='Non-dataset description'): #begin word is in the middle of the sentence begin = tokenized_sub_sentence[k] previous = tokenized_sub_sentence[k-1] if begin.startswith('Ġ'): kword = previous + begin[1:] else: kword = begin if k == (len(predicted_tokens_classes) - 1): #print('begin and end word is the last word of the sentence') kword_list.append(kword.rstrip().lstrip()) elif (j=='Dataset description') & (k>=1) & (predicted_tokens_classes[k-1]=='Dataset description'): # intermediate word of the same keyword inter = tokenized_sub_sentence[k] if inter.startswith('Ġ'): kword = kword + "" + inter[1:] else: kword = kword + " " + inter if k == (len(predicted_tokens_classes) - 1): #print('begin and end') kword_list.append(kword.rstrip().lstrip()) elif (j=='Non-dataset description') & (k>=1) & (predicted_tokens_classes[k-1] =='Dataset description'): # End of a keywords but not end of sentence. kword_list.append(kword.rstrip().lstrip()) kword = '' inter = '' else: if (j=='Dataset description'): begin = tokenized_sub_sentence[k] kword = begin kword_list.append(kword.rstrip().lstrip()) |
输出结果
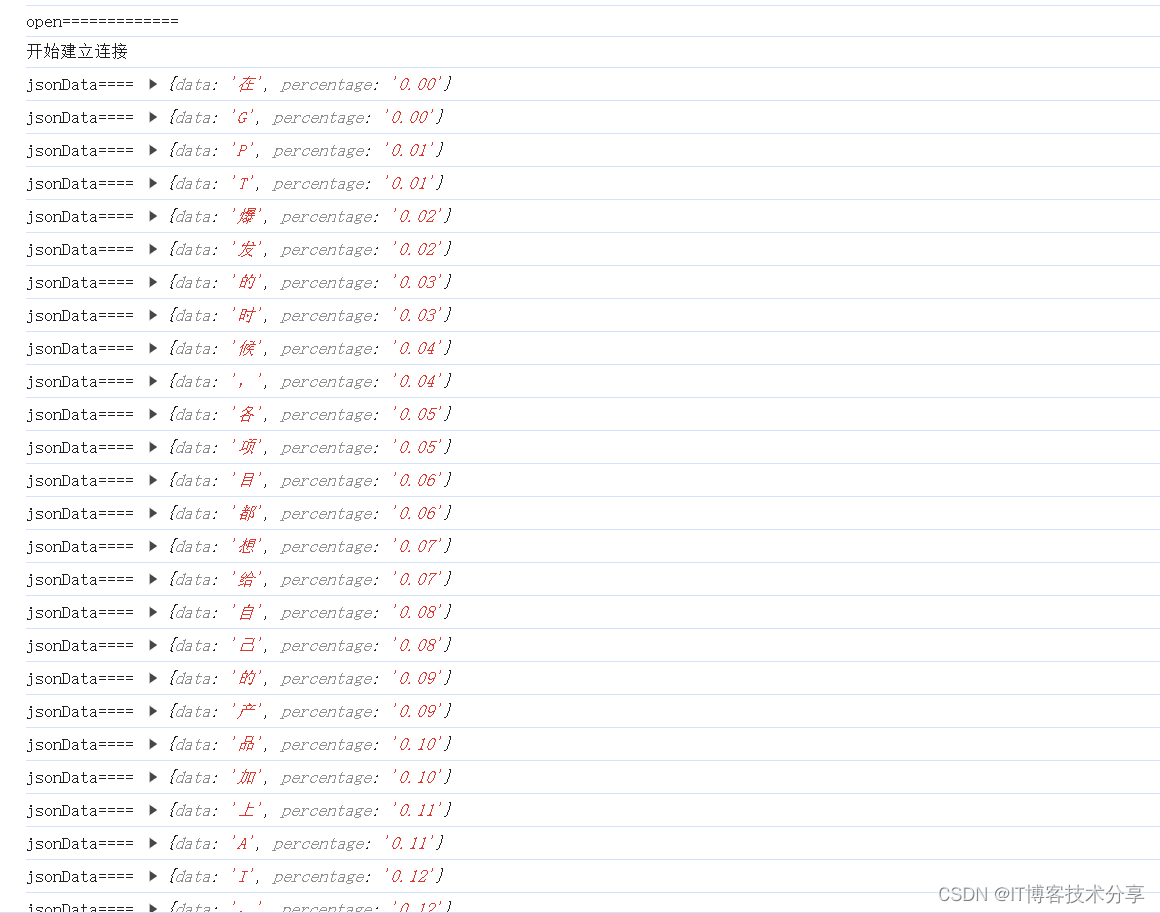
| Hug ging Face is a company based in Paris and New York tokenized_sub_sentence: ['ĠHug', 'ging', 'Face', 'Ġis', 'Ġa', 'Ġcompany', 'Ġbased', 'Ġin', 'ĠParis', 'Ġand', 'ĠNew', 'ĠYork'] kword_list shape: 2 ['ĠHug ging Face', 'Ġcompany'] kword_text: <unk> company |
Hug ging Face is a company based in Paris and New York
可以看出是Hug ging Face由于中间空格没有去除, token转id识别不出来
因此注释了输出中添加空格的代码
| # else: # kword = kword + " " + inter |
现在可以正常输出, 但是对于一个单词包含多个token的情况, 它识别出其中部分token导致输出(kword_text)不是完整单词
| tokenized_sub_sentence: ['ĠHug', 'ging', 'Face', 'Ġis', 'Ġa', 'Ġcompany', 'Ġbased', 'Ġin', 'ĠParis', 'Ġand', 'ĠNew', 'ĠYork'] ['gingFace', 'Ġcompany'] kword_text: gingFace company |
在 BPE 中,子词 token 通常以 ## 开头,表示这是前一个 token 的一部分
但这里用的是另一个字符Ġ
| from transformers import AutoTokenizer, LongformerForTokenClassification |
现在需要处理包含多个token的单词, 将包含token分类为1的单词不重复地输出
将token转换为完整单词取出
但是当后面的token在列表中, 前面的不在, 只输出了后面一半的token
| kword_list: ['ging', 'Face', 'Ġis', 'Ġa', 'Ġcompany', 'Ġbased', 'Ġin', 'ĠParis', 'Ġand', 'ĠNew', 'ĠYork'] kword_text: gingFace is a company based in Paris and New York unique_kword_list: ['ging', 'Face', 'Ġis', 'Ġa', 'Ġcompany', 'Ġbased', 'Ġin', 'ĠParis', 'Ġand', 'ĠNew', 'ĠYork'] |
合并单词
目前得到的token为tokenized_sub_sentence,
predicted_tokens_classes是针对每一个token是否符合要求的分类,
当单词中包含'Dataset description'类的token, 将该单词取出.
使用 'Ġ' 来检测新单词的开始,并将这些子词正确地连接在一起。这样可以避免不同单词被错误地连接在一起。
这个似乎是成功了
使用 'Ġ' 检测新单词的开始。
拼接属于同一个单词的 token。
如果一个单词中的任何一个 token 被预测为 'Dataset description',则将整个单词加入到 dataset_description_words 列表中。
| dataset_description_words = [] current_word = "" current_word_pred = False for token, pred_class in zip(tokenized_sub_sentence, predicted_tokens_classes): if token.startswith("Ġ"): if (len(current_word)!=0) & current_word_pred:#前面有上一个单词, 且其中有描述token, 则把它存入句子 dataset_description_words.append(current_word) current_word = token[1:] current_word_pred = (pred_class == 'Dataset description') # print("start: ",current_word) # print("dataset_description_words: ",dataset_description_words) # print("current_word_pred: ",current_word_pred) else: current_word += token current_word_pred = current_word_pred or (pred_class == 'Dataset description')#如果不是词开头, 现在token和之前已有token只要有1类的都行 # print("mid: ",current_word) # print("current_word_pred: ",current_word_pred) #最后一个单词后没有下一个单词的开始符号, 无法进入循环, 单独判断 if (len(current_word)!=0) & current_word_pred: dataset_description_words.append(current_word) |
拼接所有'Dataset description' 类 token 的单词为一个完整的字符串
| final_dataset_description_string = " ".join(dataset_description_words) |
示例分类:
| tokenized_sub_sentence: ['ĠHug', 'ging', 'Face', 'Ġis', 'Ġa', 'Ġcompany', 'Ġbased', 'Ġin', 'ĠParis', 'Ġand', 'ĠNew', 'ĠYork'] predicted_tokens_classes=['Non-dataset description', 'Dataset description', 'Non-dataset description', 'Dataset description', 'Non-dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description'] |
输出结果:
| predicted_tokens_classes ['Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Non-dataset description', 'Non-dataset description', 'Non-dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description'] tokenized_sub_sentence: ['ĠHug', 'ging', 'Face', 'Ġis', 'Ġa', 'Ġcompany', 'Ġbased', 'Ġin', 'ĠParis', 'Ġand', 'ĠNew', 'ĠYork'] dataset_description_string: HuggingFace is in Paris and New York |
运行过程:
| start: Hug dataset_description_words: [] current_word_pred: False mid: Hugging current_word_pred: True mid: HuggingFace current_word_pred: True start: is dataset_description_words: ['HuggingFace'] current_word_pred: True start: a dataset_description_words: ['HuggingFace', 'is'] current_word_pred: False start: company dataset_description_words: ['HuggingFace', 'is'] current_word_pred: True start: based dataset_description_words: ['HuggingFace', 'is', 'company'] current_word_pred: True start: in dataset_description_words: ['HuggingFace', 'is', 'company', 'based'] current_word_pred: True start: Paris dataset_description_words: ['HuggingFace', 'is', 'company', 'based', 'in'] current_word_pred: True start: and dataset_description_words: ['HuggingFace', 'is', 'company', 'based', 'in', 'Paris'] current_word_pred: True start: New dataset_description_words: ['HuggingFace', 'is', 'company', 'based', 'in', 'Paris', 'and'] current_word_pred: True start: York dataset_description_words: ['HuggingFace', 'is', 'company', 'based', 'in', 'Paris', 'and', 'New'] current_word_pred: True unfiltered_dataset_description_string: HuggingFace is company based in Paris and New York final_dataset_description_string: is based Paris and New York |
完整代码:
| from transformers import AutoTokenizer, LongformerForTokenClassification # from transformers import Trainer, TrainingArguments import torch import torch.nn as nn tokenizer = AutoTokenizer.from_pretrained("tmp/Longformer-finetuned-norm") model = LongformerForTokenClassification.from_pretrained("tmp/Longformer-finetuned-norm") # print("set num_labels begin") # 修改分类层为2分类 model.num_labels = 2 model.config.num_labels = 2 model.classifier = nn.Linear(model.config.hidden_size, model.num_labels) # 手动初始化权重 model.longformer.pooler.dense.weight.data.normal_(mean=0.0, std=model.config.initializer_range) model.longformer.pooler.dense.bias.data.zero_() # 初始化分类层权重 model.classifier.weight.data.normal_(mean=0.0, std=model.config.initializer_range) if model.classifier.bias is not None: model.classifier.bias.data.zero_()
# print("set weight zero") # 更新 id2label 和 label2id model.config.id2label = {0: 'Non-dataset description', 1: 'Dataset description'} model.config.label2id = {'Non-dataset description': 0, 'Dataset description': 1} sentence="HuggingFace is a company based in Paris and New York." inputs = tokenizer( sentence, add_special_tokens=False, return_tensors="pt" ) # print("inputs id:",inputs["input_ids"])#id无法判断token是不是同一个词, 所以不能使用 #预测 with torch.no_grad(): outputs=model(**inputs) # 如果输出是元组,可以手动解析 if isinstance(outputs, tuple): logits, = outputs else: logits = outputs.logits predicted_token_class_ids = logits.argmax(-1) # Note that tokens are classified rather then input words which means that # there might be more predicted token classes than words. # Multiple token classes might account for the same word predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]] print("predicted_tokens_classes",predicted_tokens_classes) #token类别转化为词输出 tokenized_sub_sentence = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]) print("tokenized_sub_sentence:", tokenized_sub_sentence) # 示例分类 # predicted_tokens_classes=['Non-dataset description', 'Dataset description', 'Non-dataset description', 'Dataset description', 'Non-dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description', 'Dataset description'] # 将预测类别为 'Dataset description' 的 token 所在的单词取出 dataset_description_words = [] current_word = "" current_word_pred = False for token, pred_class in zip(tokenized_sub_sentence, predicted_tokens_classes): if token.startswith("Ġ"): if (len(current_word)!=0) & current_word_pred:#前面有上一个单词, 且其中有描述token, 则把它存入句子 dataset_description_words.append(current_word) current_word = token[1:] current_word_pred = (pred_class == 'Dataset description') # print("start: ",current_word) # print("dataset_description_words: ",dataset_description_words) # print("current_word_pred: ",current_word_pred) else: current_word += token current_word_pred = current_word_pred or (pred_class == 'Dataset description')#如果不是词开头, 现在token和之前已有token只要有1类的都行 # print("mid: ",current_word) # print("current_word_pred: ",current_word_pred) #最后一个单词后没有下一个单词的开始符号, 无法进入循环, 单独判断 if (len(current_word)!=0) & current_word_pred: dataset_description_words.append(current_word) # 拼接所有包含 'Dataset description' 类 token 的单词为一个完整的字符串 dataset_description_string = " ".join(dataset_description_words) print("dataset_description_string:", dataset_description_string) ############################################################## # 训练 labels = predicted_token_class_ids # loss = model(**inputs, labels=labels).loss outputs = model(**inputs, labels=labels) if isinstance(outputs, tuple): loss,logits = outputs else: loss = outputs.loss loss_value=round(loss.item(), 2) print("loss_value",loss_value) |





![[ICS] Modbus未授权攻击S7协议漏洞利用](https://img-blog.csdnimg.cn/img_convert/b56c60c312288a5c430d374d2db43b99.jpeg)